When people think about EUDR compliance challenges, they often frame it as a volume problem. Thousands of farms, thousands of records, thousands of polygons to submit. The assumption is that more farms means more work, and that the solution is faster processing.
That is not quite right. Volume is manageable. What makes smallholder supply chains genuinely difficult is not the number of farms — it is the variation between them.
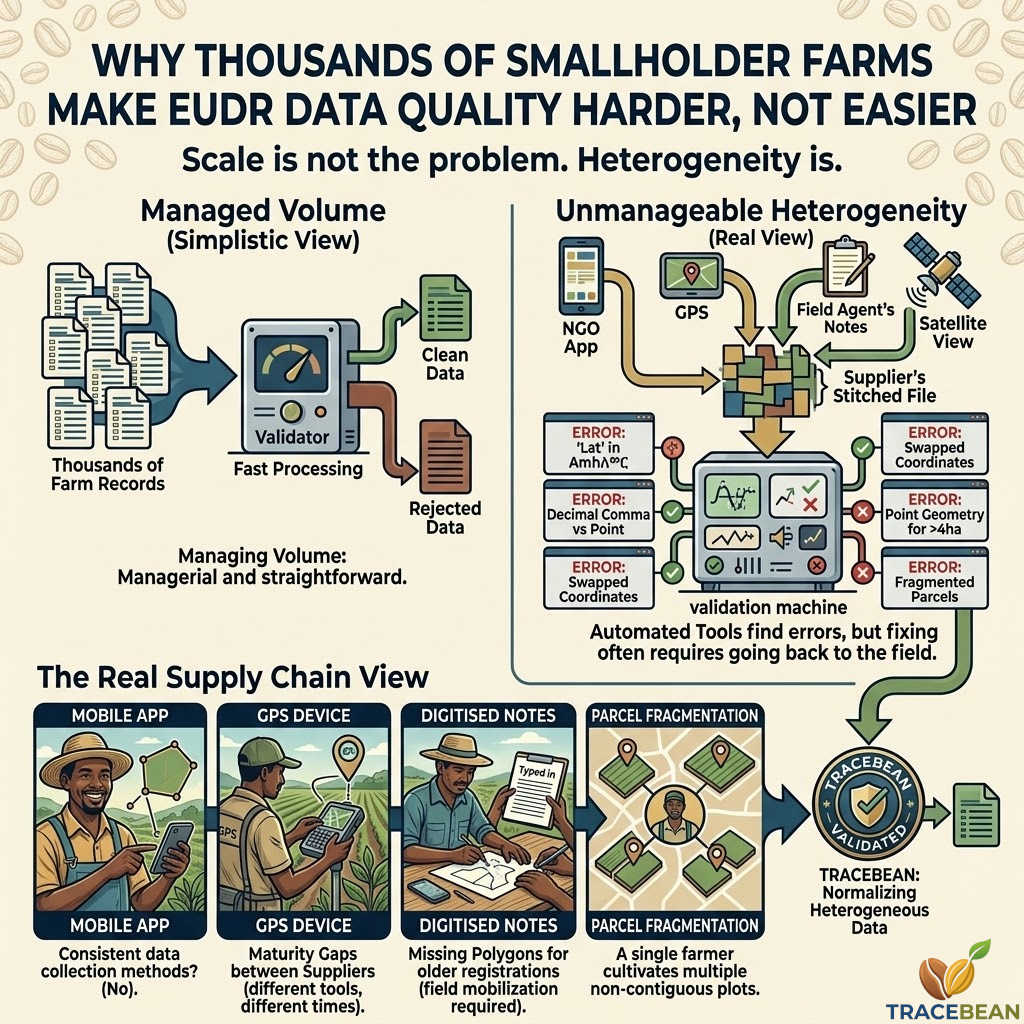
What a smallholder supply chain actually looks like
A typical European coffee importer might work with ten to thirty origin suppliers. Each supplier aggregates coffee from hundreds or thousands of individual smallholder farmers — plots of one to five hectares, often fragmented across multiple parcels, cultivated by families who have farmed the same land for generations.
Each of those farmers collected their geo-data differently. Some used a mobile app provided by an NGO. Some used a GPS device supplied by the cooperative. Some gave verbal descriptions of their plot boundaries that were later digitised by a field agent. Some were mapped by satellite. A few submitted hand-drawn sketches that someone converted into coordinates.
The result is not one dataset with thousands of records. It is hundreds of micro-datasets, each with its own format, its own field names, its own coordinate system conventions, its own error patterns — stitched together into a single file by a supplier who may not have the technical capacity to validate what they are sending.
The specific problems this creates
- Inconsistent data collection methods within a single supplier. A supplier in Honduras might have mapped farms in the western highlands using one mobile app and farms in the eastern lowlands using a different tool — because a different NGO was operating there. The two halves of the dataset arrive with different field names, different coordinate formats, and different polygon completeness rates. They need to be treated as separate data sources even though they arrived in the same file.
- Maturity gaps between suppliers. An importer working with fifteen suppliers might find that five of them have been collecting geo-data for three years and have clean, consistent records; five have been collecting for one year and have moderate error rates; and five started collecting last month and have datasets that are largely incomplete. The compliance deadline is the same for all of them.
- Missing polygons for older registrations. Farmers who registered with a cooperative ten or fifteen years ago often have only a name, a plot area in hectares, and a rough location. No coordinates. No polygon. The data was never collected because there was no regulatory reason to collect it. Getting those farmers geo-referenced before a compliance deadline is not a data cleaning problem — it is a field mobilisation problem.
- Parcel fragmentation. A single farmer might cultivate three or four non-contiguous plots — inherited land, rented plots, community land — registered under a single farm ID. The geo-data arrives as multiple features for one farmer, or as a single polygon that encompasses all plots including land the farmer does not actually cultivate. Neither representation is straightforwardly correct.
- Language and encoding issues. Field names in Amharic, Swahili, Bahasa, or Spanish with accented characters arrive in files that were not exported with UTF-8 encoding. The characters are garbled. The field that was supposed to say
Áreasaysrea. The column that should beNúcleois unreadable.
What this means for automated validation
Most of these problems are detectable. A bounds check catches coordinates outside the expected country. Fuzzy matching catches garbled field names. Geometry validation catches unclosed polygons and self-intersections. Encoding detection catches character set problems.
But detection is not the same as correction. A bounds check can tell you that a coordinate is wrong. It cannot tell you what the correct coordinate is. A geometry validator can flag a self-intersecting polygon. It cannot redraw the boundary.
This is the fundamental constraint of upstream data validation in smallholder supply chains: automated tools can find the problems reliably, but fixing them often requires going back to the source — back to the field agent, back to the farmer, back to the cooperative.
The value of automated validation is not that it eliminates all errors. It is that it separates the errors that can be fixed immediately from the errors that require human follow-up — and produces a clear, actionable report that tells the supplier exactly what needs to be done and why.
In a smallholder supply chain with thousands of farms, that distinction is the difference between a compliance process that is manageable and one that is not.
What TraceBean does with smallholder data
TraceBean is designed around the reality of heterogeneous smallholder datasets. Every file is treated as a potentially unique format. Field name matching is fuzzy, not exact. Geometry handling supports both Point and Polygon features in the same file. Error reports are farm-level, not file-level — so a supplier with 800 clean records and 47 problematic ones gets a report that shows exactly which 47 farms need attention, and why.
The goal is always the same: reduce the number of supplier follow-up rounds from three or four to one.
← Back to Blog